
Causal Inference - Lalonde dataset
Based on: https://rugg2.github.io/, https://github.com/iqDF/Lalonde-Causal-Matching
Causal Inference in Python
This notebook is an exploration of causal inference in python using the famous Lalonde dataset.
- Causal inference is a technique to estimate the effect of one variable onto another, given the presence of other influencing variables (confonding factors) that we try to keep ‘controlled’.
The study looked at the effectiveness of a job training program (the treatment) on the real earnings of an individual, a couple years after completion of the program.
The data consists of a number of demographic variables (age, race, academic background, and previous real earnings), as well as a treatment indicator, and the real earnings in the year 1978 (the response).
Robert Lalonde, “Evaluating the Econometric Evaluations of Training Programs”, American Economic Review, Vol. 76, pp. 604-620
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.formula.api as smf
# Core
import numpy as np
import scipy
import causalinference
import statsmodels.api as sm
import pylab
%matplotlib inline
sns.set_style('darkgrid')
plt.style.use('ggplot')
# Silent warnings
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
In this notebook we’ll be using the tools provided by Laurence Wong in the Package CausalInference. Comments on what each function does come from the very good package documentation: http://laurence-wong.com/software/
This package relies heavily on Rubin causal model, and so will this analysis https://en.wikipedia.org/wiki/Rubin_causal_model
The reason why several models exist is that it is impossible to observe the causal effect on a single unit, and so assumptions must be made to estimate the missing counterfactuals. We’ll explain what all that means in this post.
# https://pypi.org/project/CausalInference/
from causalinference import CausalModel
lalonde = pd.read_csv('../data/lalonde.csv', index_col=0)
lalonde.head()
| treat | age | educ | black | hispan | married | nodegree | re74 | re75 | re78 | |
|---|---|---|---|---|---|---|---|---|---|---|
| NSW1 | 1 | 37 | 11 | 1 | 0 | 1 | 1 | 0.0 | 0.0 | 9930.0460 |
| NSW2 | 1 | 22 | 9 | 0 | 1 | 0 | 1 | 0.0 | 0.0 | 3595.8940 |
| NSW3 | 1 | 30 | 12 | 1 | 0 | 0 | 0 | 0.0 | 0.0 | 24909.4500 |
| NSW4 | 1 | 27 | 11 | 1 | 0 | 0 | 1 | 0.0 | 0.0 | 7506.1460 |
| NSW5 | 1 | 33 | 8 | 1 | 0 | 0 | 1 | 0.0 | 0.0 | 289.7899 |
# let's have an overview of the data
lalonde.describe()
| treat | age | educ | black | hispan | married | nodegree | re74 | re75 | re78 | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 614.000000 | 614.000000 | 614.000000 | 614.000000 | 614.000000 | 614.000000 | 614.000000 | 614.000000 | 614.000000 | 614.000000 |
| mean | 0.301303 | 27.363192 | 10.268730 | 0.395765 | 0.117264 | 0.415309 | 0.630293 | 4557.546569 | 2184.938207 | 6792.834483 |
| std | 0.459198 | 9.881187 | 2.628325 | 0.489413 | 0.321997 | 0.493177 | 0.483119 | 6477.964479 | 3295.679043 | 7470.730792 |
| min | 0.000000 | 16.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 20.000000 | 9.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 238.283425 |
| 50% | 0.000000 | 25.000000 | 11.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 1042.330000 | 601.548400 | 4759.018500 |
| 75% | 1.000000 | 32.000000 | 12.000000 | 1.000000 | 0.000000 | 1.000000 | 1.000000 | 7888.498250 | 3248.987500 | 10893.592500 |
| max | 1.000000 | 55.000000 | 18.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 35040.070000 | 25142.240000 | 60307.930000 |
Here is the raw difference in earning between the control group and the treated group:
lalonde.groupby('treat')['re78'].agg(['median','mean'])
| median | mean | |
|---|---|---|
| treat | ||
| 0 | 4975.505 | 6984.169742 |
| 1 | 4232.309 | 6349.143530 |
The control group has higher earning that the treatment group - does this mean the treatment had a negative impact?
lalonde.groupby('treat')['re78'].plot(kind='hist', bins=20, alpha=0.8, legend=True)
treat
0 AxesSubplot(0.125,0.125;0.775x0.755)
1 AxesSubplot(0.125,0.125;0.775x0.755)
Name: re78, dtype: object
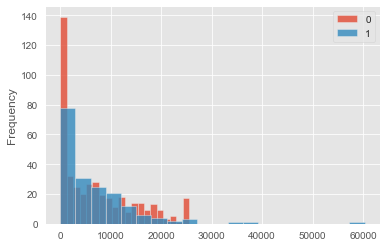
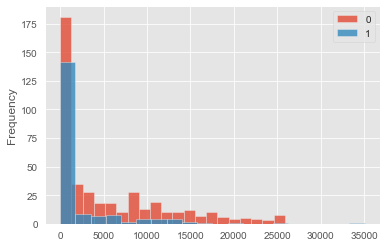
This dataset is not a balanced trial. Indeed people in the control group are very different from people in the test (treatment) group. Below is a plot of the different income distributions:
lalonde.groupby('treat')['re74'].plot(kind='hist', bins=20, alpha=0.8, legend=True)
treat
0 AxesSubplot(0.125,0.125;0.775x0.755)
1 AxesSubplot(0.125,0.125;0.775x0.755)
Name: re74, dtype: object
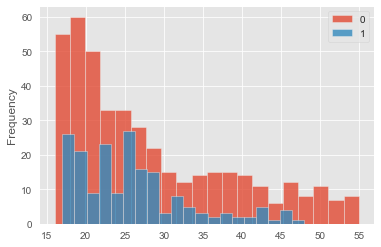
lalonde.groupby('treat')['age'].plot(kind='hist', bins=20, alpha=0.8, legend=True)
treat
0 AxesSubplot(0.125,0.125;0.775x0.755)
1 AxesSubplot(0.125,0.125;0.775x0.755)
Name: age, dtype: object
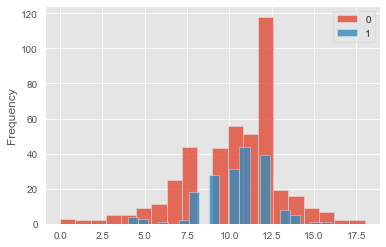
lalonde.groupby('treat')['educ'].plot(kind='hist', bins=20, alpha=0.8, legend=True)
treat
0 AxesSubplot(0.125,0.125;0.775x0.755)
1 AxesSubplot(0.125,0.125;0.775x0.755)
Name: educ, dtype: object
notation, aims and assumptions
Notations.
- Y represents the response, here is is 1978 earnings (‘re78’)
- D represents the treatment: the job training program (‘treat’)
- X represents the confounding variables, here it likely is age, education, race and marital status. X is also called a covariate or the counter factual.
Aims. What we want to know here is the Average Treatment Effect (ATE): \(\Delta = E[Y_{1} - Y_{0}]\)
However, as we saw, if we try to estimate this quantity from the row observational distribution, we get: \(\Delta_{raw} = E[Y|D=1] - E[Y|D=0] = E[Y_{1}|D=1] - E[Y_{0}|D=0] \\ \neq \Delta = E[Y_{1} - Y_{0}]\)
because: \(E[Y_{i}|D=i] \neq E[Y_{i}]\)
General problem. If we believe that age, education, race, and marital status all have a likely influence on earnings Y, we need a way to disentangle the effect of D on Y from the perturbative effect of X on Y.
Assumptions. The Causalinference package is based on a typical assumption called unconfoundedness or ignorability: \((Y(0), Y(1)) \perp D \; | \; X\)
Indeed we saw that the treatment assignment is probably not independent of each subject’s potential outcomes, e.g. poorer people are more represented in the treatment group than in the control group.
However the treatment is assumed to be unconfounded in the sense that the dependence between the treatment assignment and the outcomes is only through something we observe, namely the covariates X.
What this means is that if we control for X, i.e. look across people with similar levels of X, then the difference between treated and control should be attributable to the treatment itself, just as a randomized experiment would be.
This is the assumption, and if it doesn’t hold our results could be completely wrong.
Simple approach
The simplest type of model we can use is a linear model:
\(Y_0 = \alpha + \beta X + \epsilon\) \(Y_1 = Y_0 + \gamma D\)
If this is accurate, fitting the following model to the data using linear regression will give us an estimate of the Average Treatment Effect (ATE): \(Y = \alpha + \beta X + \gamma D\)
$\epsilon$ is called a residual and represents the noise
covariates = ['age', 'educ', 'black', 'hispan', 'married', 'nodegree', 're74', 're75']
causal.est_via_ols?
# we use the CausalModel method from the causalinference package
causal = CausalModel(
Y=lalonde['re78'].values,
D=lalonde['treat'].values,
X=lalonde[covariates].values)
causal.est_via_ols(adj=1)
# adj=1 corresponds to the simplicity of the model we entered
# This is called a "constant treatment effect"
print(causal.estimates)
Treatment Effect Estimates: OLS
Est. S.e. z P>|z| [95% Conf. int.]
--------------------------------------------------------------------------------
ATE 1548.244 734.521 2.108 0.035 108.584 2987.904
This model predicts that the Average Treatment Effect (ATE, the job training) is $1548 extra annual earnings. This is very different from our previous raw results predicting that the job training had negative effects on earnings!
Assuming that our model accurately describes the counterfactual X, CausalModel provides the 95% confidence interval. What this means is that, if we were to repeat this treatment experiment, in 95% of the cases the Average Treatment Effect would be within that interval. That doesn’t mean that the true value is within that interval.
Based on the assumption that the residuals are normally distributed, the 95% confidence interval is calculated as: \(AVG \pm 1.96 * STD / \sqrt{n}\)
In practice, as the confidence interval is very large, my interpretation is that the experiment should have had more people if a better estimate of the extra earnings was desired. Ways to control the standard deviation could also be explored.
Overall, assuming that we controlled for all the effects and did it well, it seems that the job training had a positive effect on earnings. Indeed, although the standard deviation is very large, the p value of 0.035 rejects the null hypothesis (no effect) with a confidence level of 97.5%. However, the truth is that we don’t know if we modelled the counterfactual well, and this could change everything… As we will see later, estimators such as the Ordinary Least Square (OLS) estimator can behave poorly when there is not enough covariate overlap, and that’s because the estimator needs to extrapolate too much from one group to another.
A more structured approach as we will see below can allow us to increase our confidence that the covariants are well controlled for. We will see many steps, but one simple idea is the technique of matching: the idea is to find for each sample which received the treatment a similar sample in the control group, and to directly compare these values.
formula = 're78 ~ treat + age + educ + black + hispan + married + nodegree + re74 + re75'
ols_mod = smf.ols(formula=formula, data=lalonde).fit()
print(ols_mod.summary())
OLS Regression Results
==============================================================================
Dep. Variable: re78 R-squared: 0.148
Model: OLS Adj. R-squared: 0.135
Method: Least Squares F-statistic: 11.64
Date: Fri, 29 Jan 2021 Prob (F-statistic): 5.99e-17
Time: 11:52:28 Log-Likelihood: -6297.8
No. Observations: 614 AIC: 1.262e+04
Df Residuals: 604 BIC: 1.266e+04
Df Model: 9
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 66.5145 2436.746 0.027 0.978 -4719.009 4852.038
treat 1548.2438 781.279 1.982 0.048 13.890 3082.598
age 12.9776 32.489 0.399 0.690 -50.827 76.783
educ 403.9412 158.906 2.542 0.011 91.865 716.017
black -1240.6441 768.764 -1.614 0.107 -2750.420 269.132
hispan 498.8969 941.943 0.530 0.597 -1350.983 2348.777
married 406.6208 695.472 0.585 0.559 -959.217 1772.458
nodegree 259.8174 847.442 0.307 0.759 -1404.474 1924.108
re74 0.2964 0.058 5.086 0.000 0.182 0.411
re75 0.2315 0.105 2.213 0.027 0.026 0.437
==============================================================================
Omnibus: 216.123 Durbin-Watson: 2.009
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1182.664
Skew: 1.467 Prob(JB): 1.54e-257
Kurtosis: 9.134 Cond. No. 7.64e+04
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 7.64e+04. This might indicate that there are
strong multicollinearity or other numerical problems.
Structure for a more complete approach
Pre-processing phase:
- assess covariate balance
- estimate propensity score
- trim sample
- stratify sample
Estimation phase:
- blocking estimator or/and
- matching estimator
Pre-processing phase
In the pre-processing phase, the data is inspected and manipulated to allow credible analysis to be conducted on it.
As we discussed in the previous section, one key method for disantangling the treatment effect from the covariant effects is the matching technique. In this technique we compare subjects that have similar covariate values (i.e. same age, rage, income etc). However, our ability to compare such pairs depends heavily on the degree of overlap of the covariates between the treatment and control group. This is called covariate balance.
Said otherwise, to control the effect of education, one way is to look at people in the tested group and in the non-tested group that all have the same level of education, say a bachelor degree. However, if nobody in the test group has a bachelor degree while many do in the non-test group, this procedure is impossible.
(1) assess covariate balance to assess whether how easily people can be matched. If there is too much unbalance, direct matching will rarely be possible, and we may need to use more complex techniques, if at all possible.
lalonde.columns
Index(['treat', 'age', 'educ', 'black', 'hispan', 'married', 'nodegree',
're74', 're75', 're78'],
dtype='object')
print(causal.summary_stats)
Summary Statistics
Controls (N_c=429) Treated (N_t=185)
Variable Mean S.d. Mean S.d. Raw-diff
--------------------------------------------------------------------------------
Y 6984.170 7294.162 6349.144 7867.402 -635.026
Controls (N_c=429) Treated (N_t=185)
Variable Mean S.d. Mean S.d. Nor-diff
--------------------------------------------------------------------------------
X0 28.030 10.787 25.816 7.155 -0.242
X1 10.235 2.855 10.346 2.011 0.045
X2 0.203 0.403 0.843 0.365 1.668
X3 0.142 0.350 0.059 0.237 -0.277
X4 0.513 0.500 0.189 0.393 -0.719
X5 0.597 0.491 0.708 0.456 0.235
X6 5619.237 6788.751 2095.574 4886.620 -0.596
X7 2466.484 3291.996 1532.055 3219.251 -0.287
Raw-diff is the raw difference between the means of the control and treatment groups.
As we saw previously, the treated group (trained) is earning $635 less than the control group, which is surprising.
Nor-diff in this package is Imbens and Rubin’s normalized differences (2015) in average covariates, defined as: \(\frac{\bar{X}_{k,t}-\bar{X}_{k,c}}{\sqrt{(s_{k,t}^2 + s_{k,c}^2) / 2}}\)
Here \(\bar{X}_{k,t}\) and \(s_{k,t}\) are the sample mean and sample standard deviation of the kth covariate of the treatment group, and \(\bar{X}_{k,c}\) and \(s_{k,c}\) are the analogous statistics for the control group.
The aim here is to assess the overlap between the control and treatment groups. It can be seen that X2, X4, and X6 (black, married, revenue in 1974) have a large normalized difference, beyond 0.5. This can be interpreted as an imbalance. Concretely, there are way more black people, less married people and lower income in 1974 in the treatment group than in the control group.
The impact of imbalance is to make the matching technique harder to apply. We’ll see later how we can try to correct for it (however, ideally the study would be more balanced!).
After computing this measurement for all of our features, there is a rule of thumb that are commonly used to determine whether that feature is balanced or not, (similar to the 0.05 for p-value idea).
- Smaller than 0.1 . For a randomized trial, the smd between all of the covariates should typically fall into this bucket.
- 0.1 - 0.2 . Not necessarily balanced, but small enough that people are usually not too worried about them. Sometimes, even after performing matching, there might still be a few covariates whose smd fall under this range.
- 0.2 . Values that are greater than this threshold are considered seriously imbalanced.
# Define params and inputs
covariates = ['age', 'educ', 'black', 'hispan', 'married', 'nodegree', 're74', 're75']
agg_operations = {'treat': 'count'}
agg_operations.update({
feature: ['mean', 'std'] for feature in covariates
})
def compute_table_one_smd(table_one, covariates, round_digits=4):
feature_smds = []
for feature in covariates:
feature_table_one = table_one[feature].values
neg_mean = feature_table_one[0, 0]
neg_std = feature_table_one[0, 1]
pos_mean = feature_table_one[1, 0]
pos_std = feature_table_one[1, 1]
smd = (pos_mean - neg_mean) / np.sqrt((pos_std ** 2 + neg_std ** 2) / 2)
smd = round(abs(smd), round_digits)
feature_smds.append(smd)
return pd.DataFrame({'covariates': covariates, 'smd': feature_smds})
table_one_matched = lalonde.groupby('treat').agg(agg_operations)
table_one_smd_matched = compute_table_one_smd(table_one_matched, covariates)
table_one_smd_matched
| covariates | smd | |
|---|---|---|
| 0 | age | 0.2419 |
| 1 | educ | 0.0448 |
| 2 | black | 1.6677 |
| 3 | hispan | 0.2769 |
| 4 | married | 0.7195 |
| 5 | nodegree | 0.2350 |
| 6 | re74 | 0.5958 |
| 7 | re75 | 0.2870 |
(2) Propensity Score - the probability of receiving the treatment, conditional on the covariates.
Propensity is useful for assessing and improving covariate balance. Indeed a theorem by Rosenbaum and Rubin in 1983, proves that, for subjects that share the same propensity score (even if their covariate vectors are different), the difference between the treated and the control units actually identifies a conditional average treatment effect.
Thus, instead of matching on the covariate vectors X themselves, we can also match on the single-dimensional propensity score p(X), aggregate across subjects, and still arrive at a valid estimate of the overall average treatment effect.
\[E[Y(1) - Y(0) | p(X)] \approx E[Y(1) - Y(0)]\]| This is if p(X) = P(D=1 | X), which the CausalInference package estimates for us using a sequence of likelihood ratio tests. |
reference: http://laurence-wong.com/software/propensity-score
#this function estimates the propensity score, so that propensity methods can be employed
causal.est_propensity_s()
print(causal.propensity)
Estimated Parameters of Propensity Score
Coef. S.e. z P>|z| [95% Conf. int.]
--------------------------------------------------------------------------------
Intercept -21.096 2.687 -7.851 0.000 -26.363 -15.829
X2 2.635 0.367 7.179 0.000 1.915 3.354
X4 -3.026 0.717 -4.222 0.000 -4.431 -1.621
X6 0.000 0.000 0.847 0.397 -0.000 0.000
X3 5.137 1.845 2.785 0.005 1.521 8.753
X1 1.175 0.316 3.713 0.000 0.555 1.796
X5 0.376 0.450 0.836 0.403 -0.505 1.258
X7 0.000 0.000 1.496 0.135 -0.000 0.000
X0 0.988 0.142 6.983 0.000 0.711 1.266
X0*X0 -0.015 0.002 -6.524 0.000 -0.019 -0.010
X1*X1 -0.064 0.018 -3.539 0.000 -0.099 -0.028
X6*X0 -0.000 0.000 -2.876 0.004 -0.000 -0.000
X6*X6 0.000 0.000 2.420 0.016 0.000 0.000
X3*X0 -0.223 0.081 -2.752 0.006 -0.382 -0.064
X4*X3 2.845 1.071 2.656 0.008 0.746 4.945
X2*X4 1.525 0.781 1.952 0.051 -0.006 3.055
(3) Trim sample. This excludes subjects with extreme propensity scores. Indeed it will be very hard to match those extreme subjects, so the usual strategy is to focus attention on the remaining units that exhibit a higher degree of covariate balance.
# extreme propensity is a very high probability to be either in the control group or the treatment group
# that makes matching difficult
#by default, causal.cutoff is set to 1
# the trim function will drop units whose estimated propensity score <= 0.1 or >= 0.9
#causal.cutoff = 0.1
#causal.trim()
#however, there is a procedure that tried to select an optimal cutoff value
causal.trim_s()
print(causal.summary_stats)
Summary Statistics
Controls (N_c=156) Treated (N_t=140)
Variable Mean S.d. Mean S.d. Raw-diff
--------------------------------------------------------------------------------
Y 5511.740 6023.366 6351.987 6397.833 840.246
Controls (N_c=156) Treated (N_t=140)
Variable Mean S.d. Mean S.d. Nor-diff
--------------------------------------------------------------------------------
X0 23.603 7.112 24.986 7.510 0.189
X1 10.250 2.360 10.329 2.177 0.035
X2 0.468 0.501 0.836 0.372 0.834
X3 0.250 0.434 0.071 0.258 -0.500
X4 0.263 0.442 0.221 0.417 -0.096
X5 0.647 0.479 0.664 0.474 0.035
X6 2690.978 4488.665 2110.413 4215.220 -0.133
X7 1918.904 3088.360 1635.661 3414.688 -0.087
In this new subset, the normal difference for most variables is rather balanced. Only X2 (number of black people) is still unbalanced.
It is worth noting that the initial sample of 614 people (429 controls, 185 treated) has been drastically trimmed to 297 people (157 controls, 140 treated).
In this more balanced sub-sample, without using any model, the average earnings in 1978 is more like what we would expect: populations that received training (treated) earn in average $875 more than the control group.
(4) Stratify sample - group similar subjects together. People are grouped in layers of similar propensity scores. These bins should have an improved covariate balance, and we should be able to compare and match samples within those bins.
# the default is to have 5 bins with equal number of samples
# however, it is possible to split the sample in a more data-driven way.
# The larger the sample, the more bins we can afford, so that samples can be increasingly similar within smaller bins
# the limit in dividing too much is that there are too few datapoints in each bin for the bins to be statistically different (t-test)
causal.stratify_s()
print(causal.strata)
Stratification Summary
Propensity Score Sample Size Ave. Propensity Outcome
Stratum Min. Max. Controls Treated Controls Treated Raw-diff
--------------------------------------------------------------------------------
1 0.091 0.205 67 9 0.139 0.171 1480.667
2 0.205 0.465 46 28 0.328 0.390 1105.270
3 0.466 0.676 27 46 0.555 0.579 -319.253
4 0.677 0.909 16 57 0.779 0.814 2244.311
Within bins, the raw difference in outcome should be a good representation of the real treatment effect. For example:
-
People in group 1 are unlikely to be in the treatment group (well off?). For them, the training improved their earnings by $1399 in average.
-
People in group 4 are likely to be in the treatment group (poor?). For them, the training improved their earnings even more, with a mean of $2211 for that year 1978.
Something that looks quite bad is that outcomes for the group 3 are totally different from that of the other groups.
The trend seems to be that the higher the propensity score, the higher the raw difference in outcome for each stratum. but this one shows opposite results…
This may be a sign that we haven’t controlled for enough factors (or that the propensity calculation is wrong?). Or it might also be a true representation or reality: some people may benefit from the job training, while other may not. It might also be random and the reflection that we are working with a relatively small sample (74 elements in bin 3).
Let’s see in the analysis phase if regressions within each stratum will be able to control for confounding variables better.
Estimation phase
In the estimation phase, treatment effects of the training can be estimated in several ways.
(1) The blocking estimator - although each layer of the stratum is pretty balanced and gives reasonable raw results, this estimator goes further and controls for the confounding factors within each layer of the stratum. More precisely, this estimator uses a least square estimate within each propensity bin, and from this produces an overall average treatment effect estimate.
# causal.est_via_blocking()
# print(causal.estimates)
# for some reason I'm having a singular matrix when calculating this blocking estimator
# on one of the stratum
# I've tried changing the stratum structure and the set of variables,
# however, the singularity persists when calculating the covariance matrix
# this would need a closer look at the dataset, which I haven't taken the time to do yet
# this is one of the issue of this causalinference package:
# it needs to invert large matrixes, which can fail
(2) The matching estimator - although each layer of the stratum is pretty balanced and gives reasonable raw results, this matching estimator controls for the confounding factors by matching even more thinely samples within each layer of the stratum. More precisely, this pairing is done via nearest-neighborhood matching. If the matching is imperfect, biias correction is recommended.
If issues arrive with least square, such as excessive extrapolation, this matching estimator pushes until the end the unconfoundedness assumption and nonparametrically matches subjects with similar covariate values together. In other words, if the confounding factors are equal for both element of a pair, the difference between the two will be the real treatment effect. In the causalinference package, samples are weighted by the inverse of the standard deviation of the sample covariate, so as to normalize.
Where matching discrepancy exist, least square will be used, but very locally, so large extrapolations should be less of a problem.
causal.est_via_matching(bias_adj=False)
print(causal.estimates)
Treatment Effect Estimates: Matching
Est. S.e. z P>|z| [95% Conf. int.]
--------------------------------------------------------------------------------
ATE 546.115 1211.957 0.451 0.652 -1829.321 2921.550
ATC 544.509 1502.414 0.362 0.717 -2400.223 3489.241
ATT 547.904 1389.501 0.394 0.693 -2175.519 3271.327
causal.est_via_matching(bias_adj=False)
print(causal.estimates)
Treatment Effect Estimates: Matching
Est. S.e. z P>|z| [95% Conf. int.]
--------------------------------------------------------------------------------
ATE 546.115 1211.957 0.451 0.652 -1829.321 2921.550
ATC 544.509 1502.414 0.362 0.717 -2400.223 3489.241
ATT 547.904 1389.501 0.394 0.693 -2175.519 3271.327
The model provides estimates of three quantities: ATE, ATT and ATC:
- ATE is the Average Treatment Effect, and this is what we are most interested in. \(ATE = E[Y_1-Y_0] \approx E[Y_1-Y_0 | X]\)
- Here is seems that the average effect of the treatment (job training) was to increase earnings by $384.
- However, this effect may just be a random variation, and the treatment may well not have any impact (the null hypothesis). The probability to reject the null hypothesis is 25%. The most common interpretation of this number is that the treatment of job trainings did not have a statistically significant impact on earnings, given the models and data processing we did
- ATT is the Average Treatment effect of the Treated \(ATT = E[Y_1-Y_0 | D=1]\)
- ATC is the Average Treatment effect of the Control \(ATC = E[Y_1-Y_0 | D=0]\)
# allowing several matches
causal.est_via_matching(bias_adj=True, matches=4)
print(causal.estimates)
Treatment Effect Estimates: Matching
Est. S.e. z P>|z| [95% Conf. int.]
--------------------------------------------------------------------------------
ATE 1015.624 881.557 1.152 0.249 -712.228 2743.476
ATC 711.019 1003.465 0.709 0.479 -1255.772 2677.809
ATT 1355.041 934.752 1.450 0.147 -477.073 3187.156
Allowing several matches attributes $1027 of revenue increase to the treatment, with 75% probability to be significant. A common interpretation would be still to reject this as proof of statistical significance.
Conclusions
The effect of training is hard to establish firmly. Although it seems the sample from Lalonde had positive effects, it is actually quite likely to be without any effect.
This isn’t so far from what Lalonde concluded: http://people.hbs.edu/nashraf/LaLonde_1986.pdf By glancing at it, Lalonde seemed to know the gender of participants, which does not seem to be in this dataset, or may be hidden in the NSW vs AFDC.
More work could be done to better estimate the counterfactual. For instance we could introduce polynomial variables to capture non-linear effects and/or introduce categorical variables to bin numerical variables such aseducation.
This was an example of how the CausalInference package could be used, and our conclusions are attached to those models. This package relies heavily on propensity matching and its ignorability / confoundedness assumption.
Other models exist, e.g. Bayesian models. This will be for another time for us. Meanwhile, the curious can have a look at this other post: https://engl.is/causal-analysis-introduction-examples-in-python-and-pymc.html
Alternative propensity score estimation
formula = 'treat ~ age + educ + black + hispan + married + nodegree + re74 + re75'
glm_model = smf.glm(formula=formula, data=lalonde, family=sm.families.Binomial()).fit()
glm_model.summary()
| Dep. Variable: | treat | No. Observations: | 614 |
|---|---|---|---|
| Model: | GLM | Df Residuals: | 605 |
| Model Family: | Binomial | Df Model: | 8 |
| Link Function: | logit | Scale: | 1.0000 |
| Method: | IRLS | Log-Likelihood: | -243.92 |
| Date: | Fri, 29 Jan 2021 | Deviance: | 487.84 |
| Time: | 16:17:12 | Pearson chi2: | 556. |
| No. Iterations: | 6 | ||
| Covariance Type: | nonrobust |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -4.7286 | 1.017 | -4.649 | 0.000 | -6.722 | -2.735 |
| age | 0.0158 | 0.014 | 1.162 | 0.245 | -0.011 | 0.042 |
| educ | 0.1613 | 0.065 | 2.477 | 0.013 | 0.034 | 0.289 |
| black | 3.0654 | 0.287 | 10.698 | 0.000 | 2.504 | 3.627 |
| hispan | 0.9836 | 0.426 | 2.311 | 0.021 | 0.149 | 1.818 |
| married | -0.8321 | 0.290 | -2.866 | 0.004 | -1.401 | -0.263 |
| nodegree | 0.7073 | 0.338 | 2.095 | 0.036 | 0.045 | 1.369 |
| re74 | -7.178e-05 | 2.87e-05 | -2.497 | 0.013 | -0.000 | -1.54e-05 |
| re75 | 5.345e-05 | 4.63e-05 | 1.153 | 0.249 | -3.74e-05 | 0.000 |
pscore = glm_model.predict()
# create seperate structure for data and target
treatment = lalonde['treat']
rev78 = lalonde['re78']
cleaned_df = lalonde.drop(['treat', 're78'], axis=1)
mask = lalonde['treat'] == 1
lalonde_treat = lalonde[mask]
lalonde_notreat = lalonde[~mask]
# drop labeling (e.g NSW3) from the targets data
targets = treatment.reset_index().drop('index', axis=1);
X = cleaned_df.reset_index().drop('index', axis=1);
# we seperate the pscore based on it's
# corresponding true label value
mask = targets.squeeze() == 1
pos_pscore = pscore[mask]
neg_pscore = pscore[~mask]
print('treatment count:', pos_pscore.shape)
print('control count:', neg_pscore.shape)
treatment count: (185,)
control count: (429,)
boxplot_df = pd.DataFrame({'pscore': pscore, 'treat': targets.squeeze()})
# plot boxplot
plt.figure(figsize=(10, 6))
sns.boxplot(x='treat', y='pscore', data=boxplot_df);
plt.ylabel('Propensity Score');
plt.xlabel('Treament');
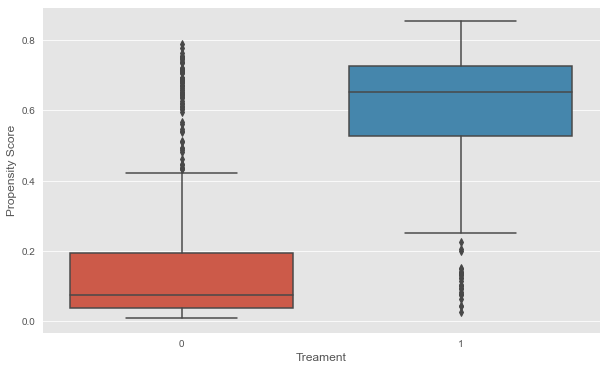
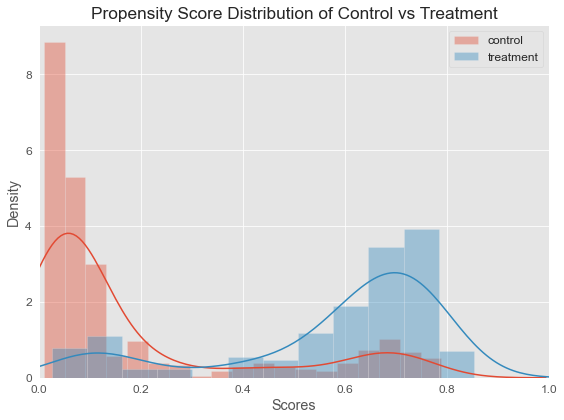
Looking at the plot below, we can see that our features, X , does in fact contain information about the user receiving treatment. The distributional difference between the propensity scores for the two group justifies the need for matching, since they are not directly comparable otherwise.
Although, there’s a distributional difference in the density plot, but in this case, what we see is that there’s overlap everywhere, so this is actually the kind of plot we would like to see if we’re going to do propensity score matching.
What we mean by overlap is that no matter where we look on the plot, even though there might be more control than treatment or vice versa, there will still be some subject from either group.
The notion of overlap means that our positivity assumption is probably reasonable. Remember positivity refers to the situation where all of the subjects in the study have at least some chance of receiving either treatment. And that appears to be the case here, hence this would be a situation where we would feel comfortable to proceed with our propensity score matching.
# change default style figure and font size
plt.rcParams['figure.figsize'] = 8, 6
plt.rcParams['font.size'] = 12
sns.distplot(neg_pscore, label='control')
sns.distplot(pos_pscore, label='treatment')
plt.xlim(0, 1)
plt.title('Propensity Score Distribution of Control vs Treatment')
plt.ylabel('Density')
plt.xlabel('Scores')
plt.legend()
plt.tight_layout()
plt.show()
# Define params and inputs
mask = lalonde['treat'] == 1
covariates = ['age', 'educ', 'black', 'hispan', 'married', 'nodegree', 're74', 're75']
agg_operations = {'treat': 'count'}
agg_operations.update({
feature: ['mean', 'std'] for feature in covariates
})
from sklearn.neighbors import NearestNeighbors
# Helper function that uses K-NN algorithm to calculate
# similarity distance and get the similarity indices for matching
def get_similar(pos_pscore, neg_pscore, topn=5, n_jobs=1):
knn = NearestNeighbors(n_neighbors=topn + 1, metric='euclidean', n_jobs=n_jobs)
knn.fit(neg_pscore.reshape(-1, 1))
distances, indices = knn.kneighbors(pos_pscore.reshape(-1, 1))
sim_distances = distances[:, 1:]
sim_indices = indices[:, 1:]
return sim_distances, sim_indices
sim_distances, sim_indices = get_similar(pos_pscore, neg_pscore, topn=1)
# Display matching table
df_pos = lalonde[mask]
df_neg = lalonde[~mask].iloc[sim_indices[:, 0]]
df_matched = (df_pos.reset_index(drop=True)
.merge(df_neg.reset_index(drop=True),
left_index=True,
right_index=True))
num_matched_pairs = df_neg.shape[0]
print('Number of matched pairs: ', num_matched_pairs)
df_matched
Number of matched pairs: 185
| treat_x | age_x | educ_x | black_x | hispan_x | married_x | nodegree_x | re74_x | re75_x | re78_x | treat_y | age_y | educ_y | black_y | hispan_y | married_y | nodegree_y | re74_y | re75_y | re78_y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 37 | 11 | 1 | 0 | 1 | 1 | 0.00 | 0.00 | 9930.0460 | 0 | 55 | 4 | 1 | 0 | 0 | 1 | 0.0000 | 0.0000 | 0.00000 |
| 1 | 1 | 22 | 9 | 0 | 1 | 0 | 1 | 0.00 | 0.00 | 3595.8940 | 0 | 26 | 8 | 0 | 1 | 0 | 1 | 3168.1340 | 5872.2580 | 11136.15000 |
| 2 | 1 | 30 | 12 | 1 | 0 | 0 | 0 | 0.00 | 0.00 | 24909.4500 | 0 | 26 | 12 | 1 | 0 | 0 | 0 | 0.0000 | 1448.3710 | 0.00000 |
| 3 | 1 | 27 | 11 | 1 | 0 | 0 | 1 | 0.00 | 0.00 | 7506.1460 | 0 | 18 | 11 | 1 | 0 | 0 | 1 | 0.0000 | 1367.8060 | 33.98771 |
| 4 | 1 | 33 | 8 | 1 | 0 | 0 | 1 | 0.00 | 0.00 | 289.7899 | 0 | 19 | 11 | 1 | 0 | 0 | 1 | 5607.4220 | 3054.2900 | 94.57450 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 180 | 1 | 33 | 12 | 1 | 0 | 1 | 0 | 20279.95 | 10941.35 | 15952.6000 | 0 | 17 | 11 | 0 | 1 | 0 | 1 | 0.0000 | 873.6774 | 7759.54200 |
| 181 | 1 | 25 | 14 | 1 | 0 | 1 | 0 | 35040.07 | 11536.57 | 36646.9500 | 0 | 32 | 15 | 0 | 0 | 0 | 0 | 489.8167 | 968.5645 | 7684.17800 |
| 182 | 1 | 35 | 9 | 1 | 0 | 1 | 1 | 13602.43 | 13830.64 | 12803.9700 | 0 | 52 | 8 | 1 | 0 | 1 | 1 | 5454.5990 | 666.0000 | 0.00000 |
| 183 | 1 | 35 | 8 | 1 | 0 | 1 | 1 | 13732.07 | 17976.15 | 3786.6280 | 0 | 47 | 10 | 1 | 0 | 0 | 1 | 21918.3200 | 4323.6290 | 19438.02000 |
| 184 | 1 | 33 | 11 | 1 | 0 | 1 | 1 | 14660.71 | 25142.24 | 4181.9420 | 0 | 18 | 9 | 1 | 0 | 0 | 1 | 1183.3970 | 1822.5480 | 803.88330 |
185 rows × 20 columns
Assess covariate balance after matching. For this, compute the absolute standardized differences in means in the covariates after matching (Rosenbaum and Rubin, 1985), \(ASMD_a(x)=\frac{\bar{x}_{t,a}-{\bar{x}_{c,a}}}{\sqrt{\frac{s^{2}_{t,b} + s^{2}_{c,b}}{2}}},\) where \(\bar{x}_{t,a}\) and \(\bar{x}_{c,a}\) are, respectively, the means of covariate $x$ in the treatment and control groups after matching, and \(s^{2}_{t,b}\) and \(s^{2}_{c,b}\) are, correspongdingly, the sample variances treatment and control groups before matching. (One reason to use the sample variances before matching rather than the sample variances after matching is to free the comparisons of the means after matching from simultaneous changes in the variances.) Comment on covariate balance.
# Create matching table
df_pos = lalonde[mask]
df_neg = lalonde[~mask].iloc[sim_indices[:, 0]]
df_matched = pd.concat([df_pos, df_neg], axis=0) # this time we join by axis-0
# Calculate Rosenbaum ASMD
table_one_matched = df_matched.groupby('treat').agg(agg_operations)
table_one_smd_matched = compute_table_one_smd(table_one_matched, covariates)
table_one_smd_matched
| covariates | smd | |
|---|---|---|
| 0 | age | 0.0234 |
| 1 | educ | 0.0965 |
| 2 | black | 0.0147 |
| 3 | hispan | 0.0438 |
| 4 | married | 0.1157 |
| 5 | nodegree | 0.1098 |
| 6 | re74 | 0.0700 |
| 7 | re75 | 0.0576 |
# pair t-test
ttest = scipy.stats.ttest_rel(df_pos['re78'].values, df_neg['re78'].values)
print("The statistic of t-test:", ttest.statistic)
print("The p-value of t-test:", ttest.pvalue)
df_pos['re78'].mean() - df_neg['re78'].mean()
The statistic of t-test: 1.8691170316786174
The p-value of t-test: 0.0631955759711721
1411.4997588108117